Articos: research you can audit in 30 minutes
Six months designing an AI research-report generator that survives the strict-reader test. This is what it looks like when a senior researcher has to defend the output. I led the research, the experience, and the production build.
Overview
Traditional user research costs $5k–$30k per study and takes weeks. That blocks agencies on five-day timelines, SaaS teams shipping weekly, and founders without budget. Most AI research tools collapsed into chat wrappers that produce fluent-but-unfaithful interviews. The hard problem is generating one a senior UX researcher would put their name on. I led the research, design, and production build of Articos around a single principle: the product refuses to ship a report it cannot defend.
01 · The bar: a report a senior UXR would sign
We built the rubric before the prompt. Optimize for fluency and the work fails on contact with someone who reads Baymard and NN/g. Six criteria, each scored against every draft before any model call shipped:
The rubric became an executable eval harness. Forty-seven studies routed through it; 36 passed the citation-traceability check; the other 11 exposed exactly the failures the rubric named. Evidence specificity was the hardest pass. First-pass synthesis produced confident-but-unsourced claims at 38% of the rate of the final pipeline. Closing that gap is the rest of this case study.

Decision · build the rubric before the prompt. Without an external quality target, the model optimizes for fluency, which a senior researcher dismisses in the first paragraph. Tradeoff: two weeks delaying the demo. Stakeholders wanted a working pipeline. I shipped a rubric instead.
02 · Where the model ends and the user begins
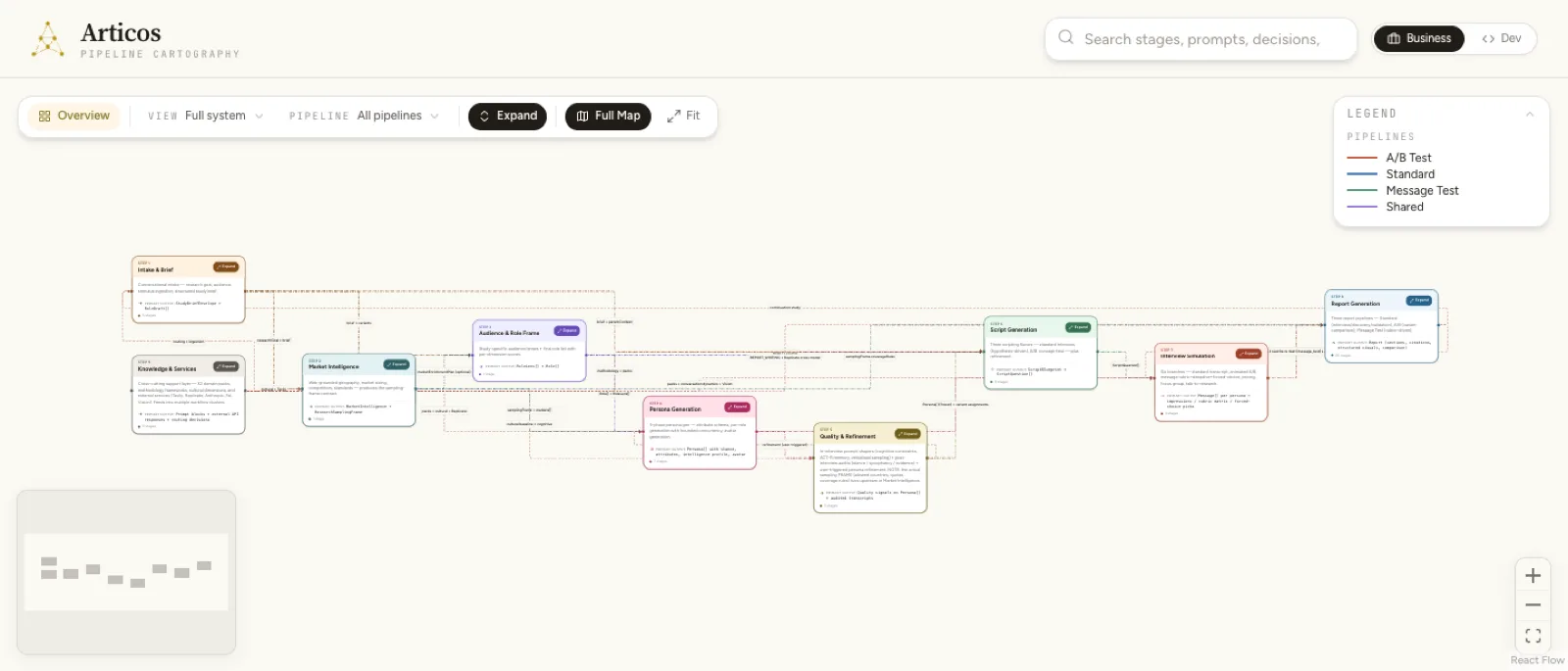
The report pipeline is an 8-stage service blueprint. Each stage exists because of one specific failure mode the model produces when left alone. So the guardrail and the recovery path are the design surface, and the model is the implementation detail.
- Themes. Surface 8–12 candidate themes; reject any lacking 3+ source paragraphs. Catches: generic theme drift.
- Web research. Theme-informed parallel calls with provenance; de-dupe and drop low-authority. Catches: citation hallucination.
- Blueprint. Section and claim skeleton; cap unanimity confidence at 75%; inject a refuting-source pass. Catches: overconfident synthesis.
- Critique. Self-critique against a 13-item cliché blocklist plus a 5-dimension sycophancy detector. Catches: false authority.
- Repair. Targeted rewrite that must preserve source pins; diff view. Catches: repair drift.
- Sections. Coherent prose, citation coverage ≥95% per section. Catches: section incoherence.
- Exec rewrite. Summarize for a non-researcher; no new claims allowed. Catches: new-claim drift.
- Polish. Prose, bias, and visual audit; no change that alters claim semantics. Catches: semantic drift.
Personas are generated from a curated library of 14 lenses. The model picks 4 per
study but cannot invent lenses outside the library. The library is the guardrail, and stable
names let researchers build intuition across studies (e.g. adoption_stance: Skeptic vs
Pragmatist). Three of the fourteen:
Decision · hide the hypothesis from the model during generation. Confirmation bias is the failure mode fluent models produce by default. The script-generation service receives only role names and counts, never the hypothesis, which is contested against the evidence only at synthesis. Researchers asked to feed the model their hypothesis upfront (“it would be faster”). I shipped the friction instead, so the output can answer “did the model already know what you wanted to find?”
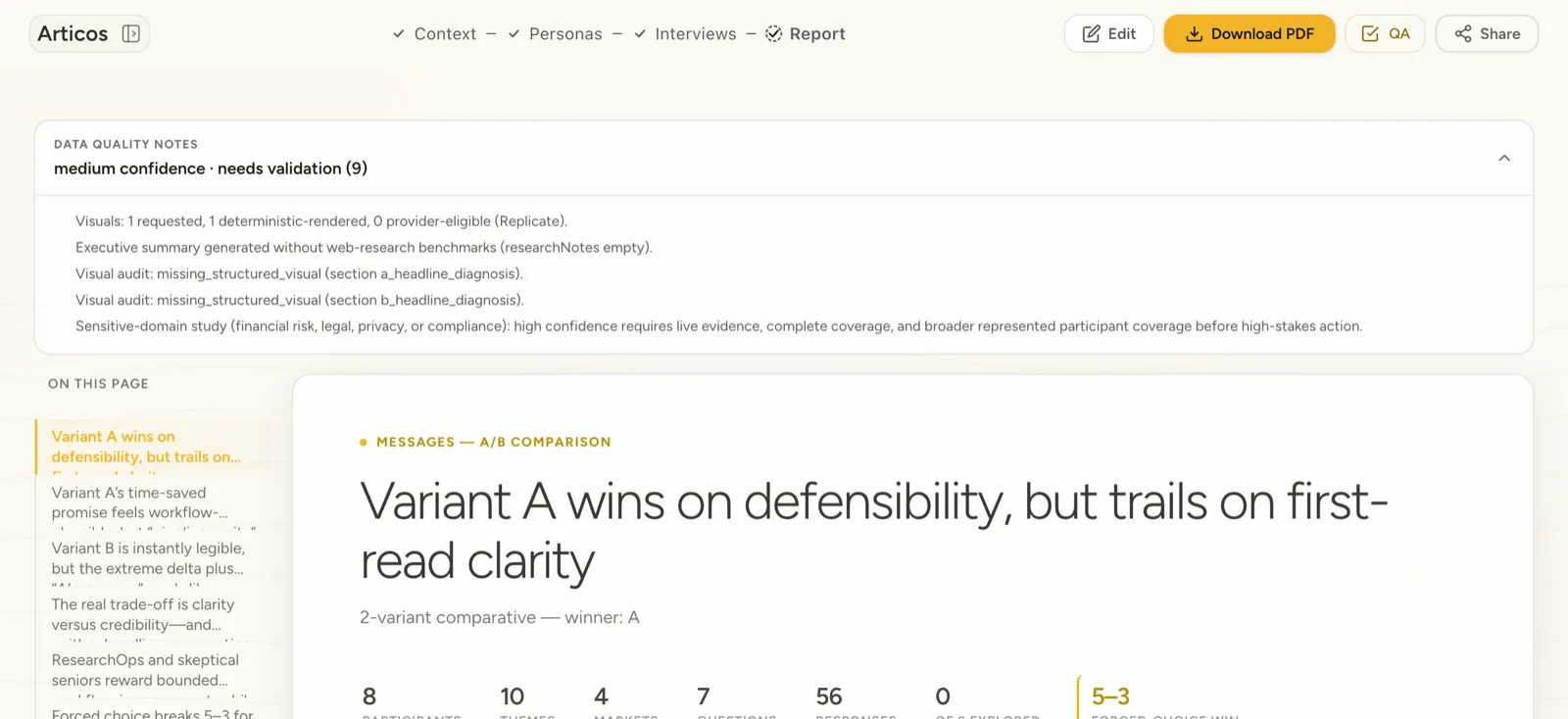
03 · Five screens, four receipts
Five screens carry the work: brief, lens, critique, repair, export. Each one is a decision the user owns. Everything else (settings, history, share) sits in side panels. Brief is where the model becomes accountable; lens is where the user picks which strict reader to invoke; critique is the first place the model can refuse; repair is the first place the user can refuse the model; export is where the audit trail lands.
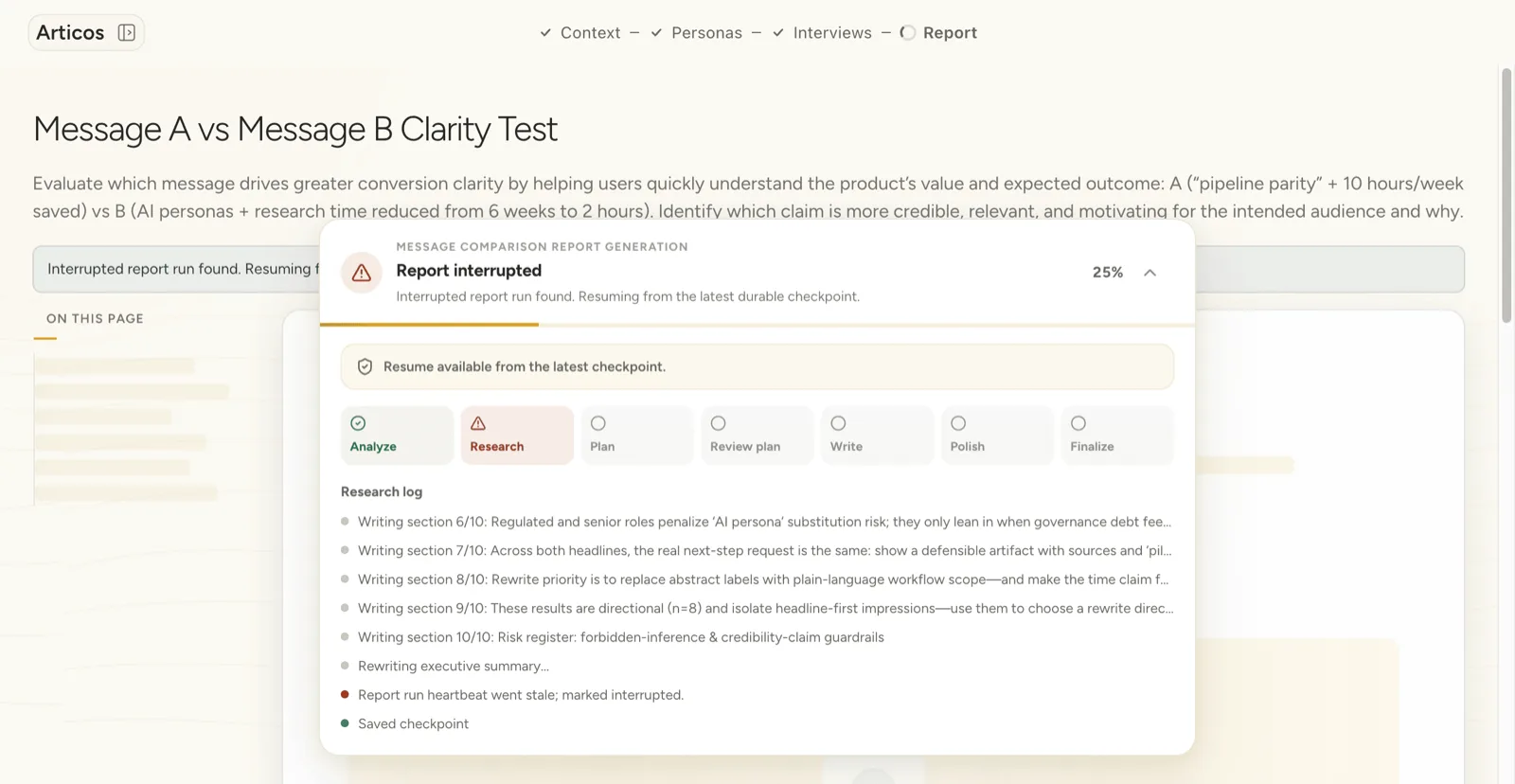

Then the four receipts. Each one names a failure we shipped, the reviewer feedback that caught it, and the fix now in production:
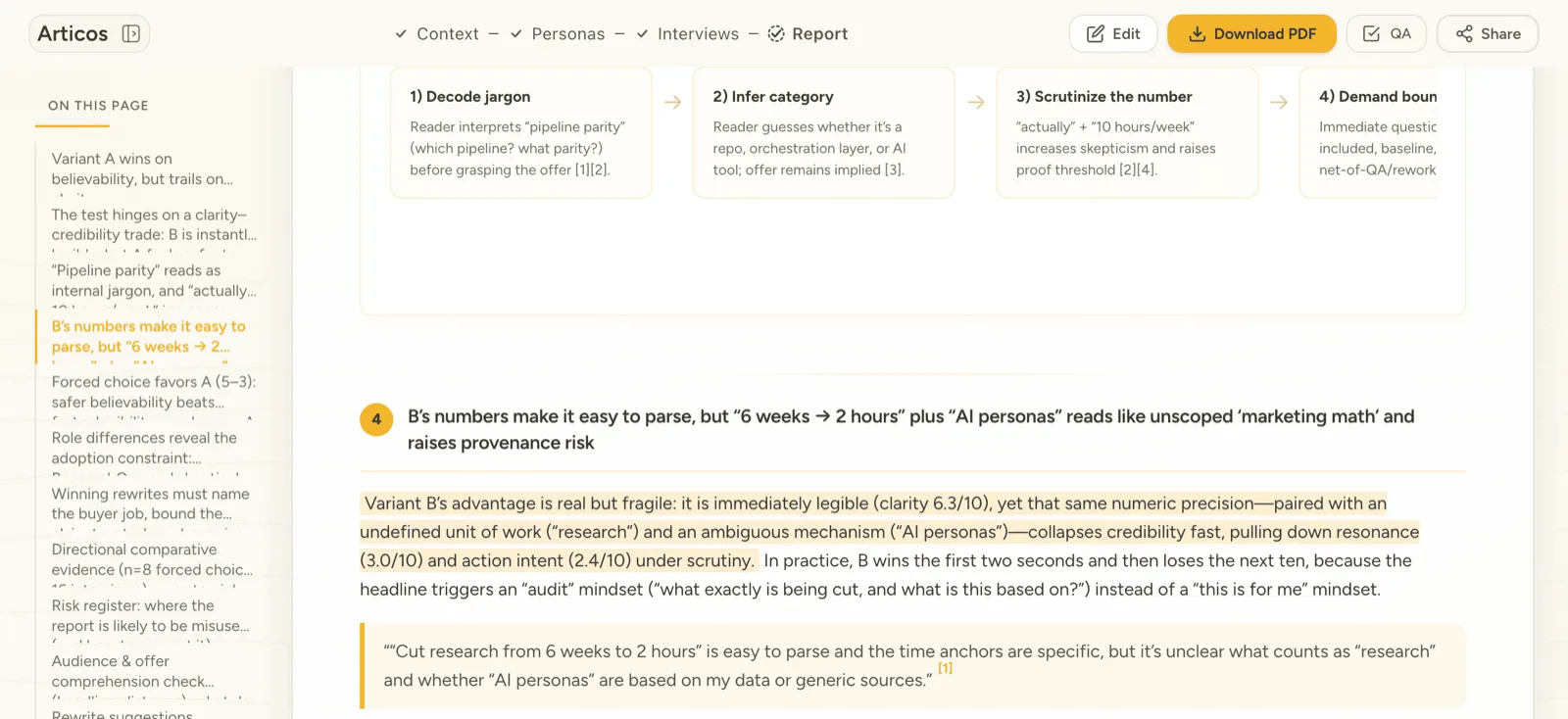
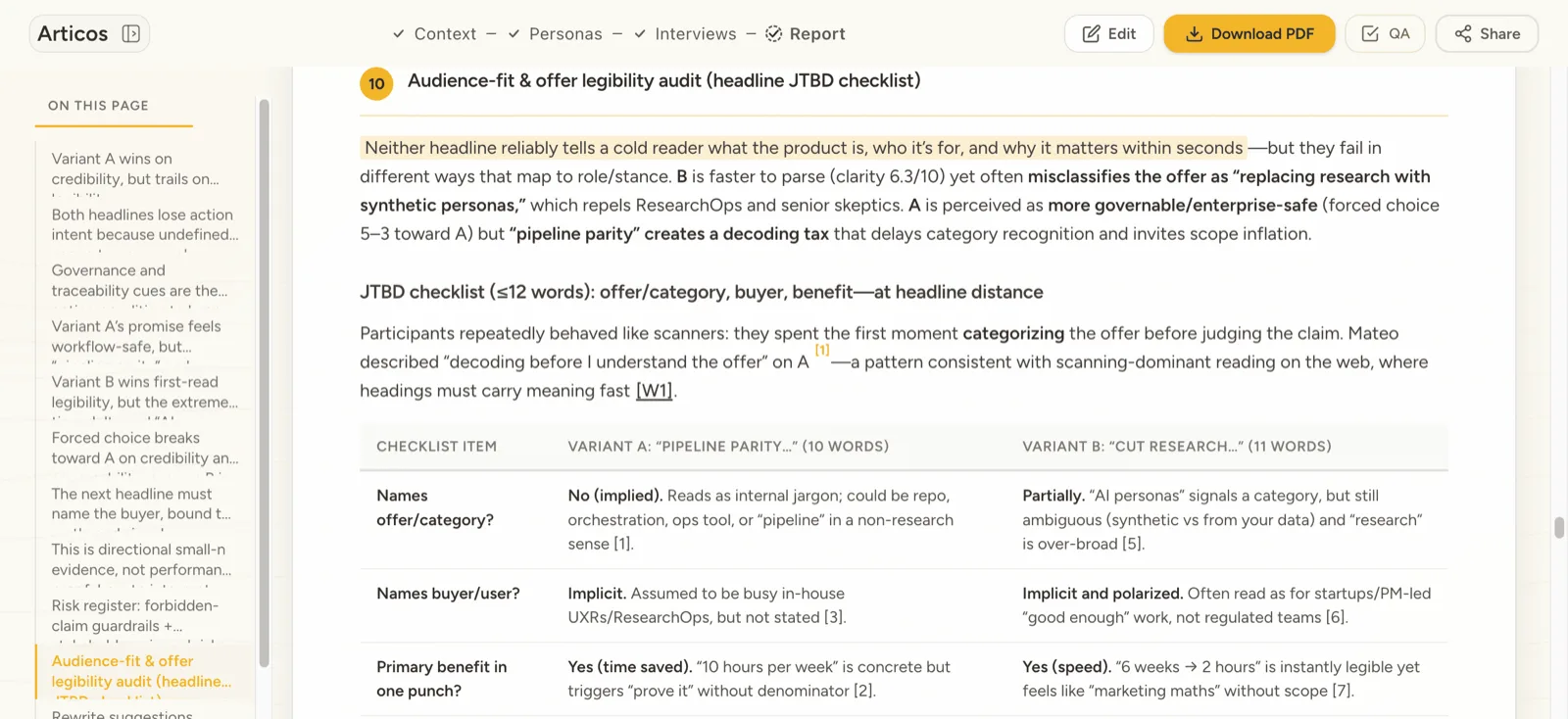

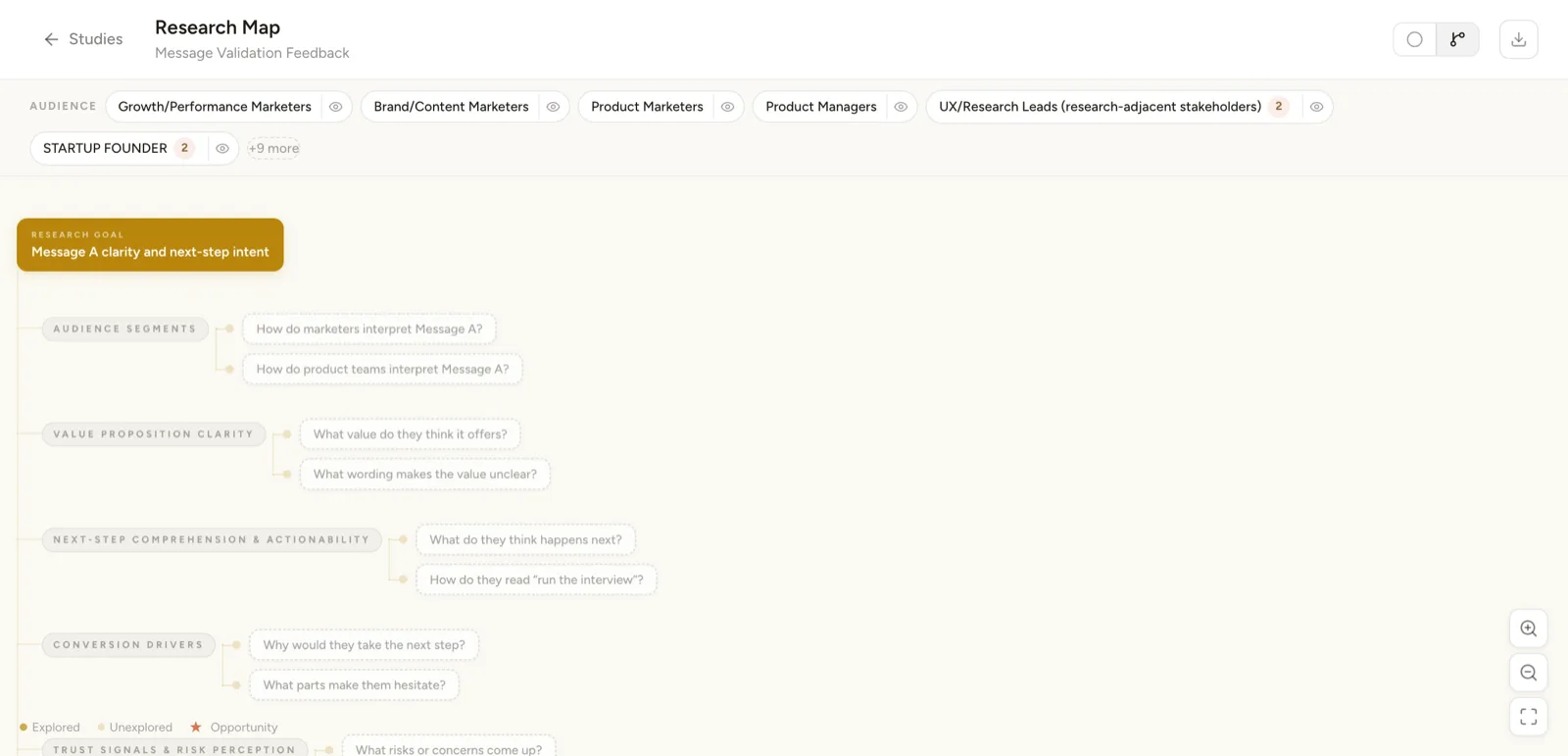
Decision · kill the one-click “generate full report” button. Stakeholders asked for it; the reports were polished but undefendable. Telemetry: 100% of one-click reports were edited before share. In the week-six survey, four of five researchers said the friction made them more confident in the output. I lost the demo line. I kept the reason a researcher would put their name on the work.
04 · What worked, what didn’t, what’s next
Validation harness. 47 studies routed through Articos; 36 passed end-to-end with citation traces verified and themes mapped to source paragraphs at the sentence level; 11 were excluded on citation issues the eval caught before any human saw the output. Theme recall across the 47-study set was 86.1%; RFI (Recall-Filtered Insight) was 0.814; 358 ground-truth themes recovered across 10 domains. The eval data is publicly inspectable.
The live product. Over the same six months, articos.com grew from 455 active users (Nov 2025) to 4,411 (Apr 2026), roughly 10× growth. GA4 over the window: 16,984 active users, 26,019 sessions, 62,723 page views, 41.7% engagement rate, 34-minute average session. Earned coverage from TLDR Design (1,716 sessions), Superhuman, and There’s An AI For That. Plus inbound ChatGPT referrals, the assistant recommending the product as an answer. Spread across US, UK, Canada, Singapore, Germany, and Australia.
What didn’t work. Two things stay open. The product can’t yet grade source authority at the paragraph level for non-English corpora, and it can’t reliably catch a sophisticated false-authority pattern (a real-but-irrelevant citation). The methods-auditor lens gets the egregious cases; the subtle ones still pass.
What’s next. (1) Claim-level evidence grading, with confidence derived from source strength, not model self-report. (2) Team review, where research leads overlay their critique on the system’s without rewriting the section. (3) The eval harness in production: if the system can’t defend a report by its own rubric, it refuses to export.
The product refuses to ship a report it cannot defend. The refusal is the feature.
The eval harness, confidence caps, and hypothesis-blind generation here are the applied form of Grounded Simulation, the architecture I wrote up for faithful synthetic UX research. For the formal paper and the rest of my auditable AI research, see the research page.
Methodology & sources
Six months · ~37 LLM service files · 13 screens · 8-stage report pipeline · 47 studies through the validation harness (36 verified end-to-end). Grounded in literature including Weisz et al., Design Principles for Generative AI Applications (CHI 2024); De-skilling, Cognitive Offloading, and Misplaced Responsibilities (CHI 2025 EA); The trust crisis in artificial intelligence (Technology in Society, 2026); and HAX: Designing the Internet of Agents (arXiv 2025).